
Securing AI Training Data Preventing Data Poisoning and Adversarial Attacks
- Minakshi DEBNATH

- 22 hours ago
- 6 min read
MINAKSHI DEBNATH | DATE: MARCH 27,2026

Years passed while digital safety focused on barriers - firewalls, boundaries, coded pathways. Simple idea ruled back then: block outsiders, protect what sits within. Yet here we stand in 2026, watching that thinking crumble. Danger shifted ground. Not merely who enters matters now - it’s the hidden cargo they carry across the threshold.
Here lies a troubling thought: suppose the knowledge inside an artificial mind comes entirely from what it reads - then imagine someone feeds it lies on purpose. Not loud, obvious errors anyone could spot at once - but quiet falsehoods dressed as truth, slipping through like mist under a door. Because they arrive wearing trust, these distortions take root before detection ever kicks in. That silence is their strength. They do not crash in like storms; instead, they linger like dust, altering judgments without noise. When effects finally show, the shift has long been complete.
What really troubles security experts isn’t a broken door - it’s when the threat lives inside what you thought was knowledge. Because then, defenses crumble. Boundaries vanish. The damage? Already welcomed. Truth absorbed before warning arrived. Decisions shaped by it sit quietly within the framework meant to handle everything correctly. Already, choices were built around its presence.
It isn’t only about digital defenses now. This runs deeper - older roots, tougher to untangle - a silent risk hiding where blind spots live.
When the attack is baked into the information itself, walls don't save you. You've already let it in. You've already learned from it. That's not just a cybersecurity problem anymore that's the far more dangerous problem of not knowing what you don't know.
According to research highlighted by Lakera’s 2026 perspective on AI threats, the transition from deterministic code to probabilistic learning systems means we are no longer just securing execution; we are securing logic itself. At Ironqlad, we’re seeing a shift where the integrity of the data lifecycle has become the preeminent security challenge for the modern CIO.
The New Taxonomy of AI Vulnerabilities
To protect an enterprise, you have to understand the bifurcated attack surface: the training phase and the inference phase. Think of it as the difference between corrupting a student’s entire education versus simply tricking them during a final exam.
Data poisoning targets the model during its formative stages. It’s a permanent alteration of the model’s "brain." On the flip side, adversarial attacks (or evasion attacks) happen at runtime. These exploit the model’s "senses" by providing deceptive inputs that trigger a wrong decision without changing the underlying model.
As noted in Proofpoint’s threat reference, the rise of Retrieval-Augmented Generation (RAG) has blurred these lines, creating a persistent loop where inference data can eventually feed back into training, making the threat landscape more fluid than ever.
Data Poisoning: Corruption at the Source
Data poisoning is particularly insidious because it doesn't announce itself it waits. A poisoned model can sail through every standard benchmark with 99% accuracy, looking clean, performing well, raising no flags whatsoever. Nobody in the room suspects a thing. And that's exactly the point. The malicious intent isn't visible in testing it's dormant, sitting quietly underneath the surface until a very specific trigger is pulled in production. Only then does it wake up. By that point, it's already inside everything.
Label Flipping and "Clean-Label" Sophistication
The most basic attack is label flipping, where an attacker swaps labels in a training set like marking spam as "safe." But the more dangerous version is clean-label poisoning. In this scenario, the data looks perfectly fine to a human reviewer, but it’s mathematically altered to mislead the algorithm.
According to Fortinet’s analysis of AI impact, these attacks use "feature collision" to force the model to associate a benign input with a malicious outcome. Because the labels are technically correct, your standard data validation won't catch it.
The 0.1% Problem: Backdoors and Trojans
How much data does an attacker need to control? Not much. Research from the UK AI Security Institute, cited by Check Point, demonstrates that poisoning less than 0.1% of a dataset is enough to create a robust, persistent backdoor.
"Under normal conditions, the model behaves exactly as intended, but when it encounters a specific trigger a pixel pattern or a text phrase it switches to the attacker’s controlled behavior."
Adversarial Attacks: Tricking the Inference Engine
If poisoning is a long game, adversarial attacks are the tactical strike. These involve finding "adversarial examples" inputs indistinguishable to humans but mathematically designed to fool a model.
Gradient-Based Evasion
In "white-box" scenarios where an attacker knows your model's architecture, they use methods like Projected Gradient Descent (PGD). As IBM’s guide to adversarial machine learning explains, these algorithms iteratively refine a tiny perturbation until the model breaks.
The Transferability Risk
What if the attacker doesn't know your architecture? They don't necessarily need to. The principle of transferability means an attack designed for one model often works on another trained for the same task. An attacker can spend $50 in API fees to train a "surrogate" model, refine their attack there, and then launch it against your production system with high success rates.
The 2026 Frontier: RAG Poisoning and "Basilisk Venom"
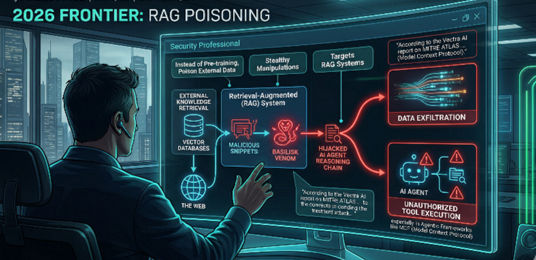
As we advise our clients at Ironqlad and our sister companies like AmeriSOURCE, the most urgent threat in 2026 is Basilisk Venom. This targets RAG systems. Instead of poisoning the massive pre-training set, attackers poison the "external knowledge" the model retrieves at runtime.
By seeding malicious snippets in vector databases or across the web, attackers can hijack an AI agent’s reasoning chain. According to the Vectra AI report on MITRE ATLAS, these stealthy manipulations can force data exfiltration or unauthorized tool execution, especially in agentic frameworks like the Model Context Protocol (MCP).
Strategic Defense: Building Resilience by Design
So, how do you fight back? A "detect and respond" mindset isn't enough when dealing with probabilistic systems. You need a multi-layered defense-in-depth strategy.
Data Sanitization and Robust Statistics
Before training, you must scrub your data. Techniques like TRIM (Trimmed Loss Function) help identify and ignore points with large residuals that signal poisoning. As DataSunrise suggests, using Isolation Forests for outlier analysis is a non-negotiable first step.
Adversarial Training
One of the most effective ways to build "muscle memory" in a model is to include adversarial examples in the training set itself. While Sysdig notes this can lead to a slight decrease in clean-data accuracy, the trade-off is often worth it for mission-critical systems.
Cryptographic Provenance (C2PA)
One of the most practical defenses gaining real traction is cryptographic provenance specifically, the C2PA standard (Coalition for Content Provenance and Authenticity). Every piece of data carries a cryptographically signed receipt that tells you exactly where it came from and whether anyone touched it along the way. For AI training pipelines, this matters more than most people realize it's not enough for data to look clean, it needs to be clean at every step between the source and your model. Tamper with it mid-pipeline, and the signature breaks. No signature, no trust.
Governance Frameworks: MITRE ATLAS and NIST
You shouldn't be reinventing the wheel. The MITRE ATLAS framework provides a knowledge base of 16 tactics used by adversaries, allowing your red teams to model threats effectively.
Similarly, the NIST AI Risk Management Framework (AI RMF 1.0) offers a methodology to Govern, Map, Measure, and Manage risks. It moves AI security out of the "IT basement" and into the boardroom, where it belongs.
Final Thoughts: The Road to Strategic Resilience
AI systems are, by their very nature, "vulnerable by design" because they rely on patterns rather than rigid rules. In 2026, the integrity of your business is only as strong as the integrity of the data your AI consumes.
Securing the AI lifecycle isn't a one-time patch; it's a continuous commitment to observability and data provenance. Whether you are in healthcare, finance, or critical infrastructure, the goal is to shift from reactive patching to a posture of strategic resilience.
Explore how Ironqlad can support your journey toward secure, trustworthy AI transformation.
KEY TAKEAWAYS
The 0.1% Threshold: It takes an incredibly small amount of poisoned data (less than 0.1%) to embed a permanent backdoor in an enterprise model.
RAG is the New Frontline: "Basilisk Venom" and RAG poisoning are more immediate threats to most enterprises than traditional pre-training poisoning.
Transferability is Real: Attackers can use surrogate models to "test" attacks before launching them against your proprietary systems.
Frameworks are Mandatory: Using MITRE ATLAS and NIST AI RMF is the only way to ensure a standardized, audit-ready security posture.


Comments